|
||
 |
| Home |
| Who Is Stone Marmot? |
| Hear Our Music |
| Read Our Lyrics |
| Buy Our Music and Merchandise |
| News |
| Rants and Raves |
| Contact Us |
|
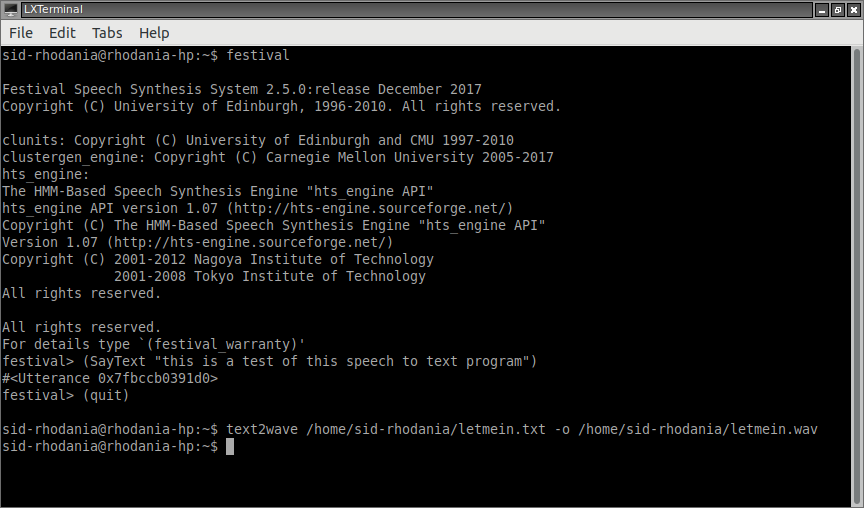
How We Did The "Let Me In" Computer Generated Vocals By Sid of Stone Marmot July 30, 2019 [Updated Nov. 4, 2020] I use a version of Linux (mostly Lubuntu) for almost everything I do on the computer. About the only things I still do with Windows are my audio recording and processing, which is done with an old version of Cakewalk Sonar, and our animation, which is done with an old version of Toon Boom, both on an old Windows XP computer. I was investigating possible Linux replacements for Sonar when I stumbled upon various text-to-speech (TTS) converter software. Versions of TTS software are often used for Siri, Alexa, children's speaking toys, telephone answering machines and voice messaging services, for example. I had experimented with various Windows-based TTS converters about five years ago, but found that their resulting audio all sounded pretty phony. I tried some of these Linux based ones and they also sounded pretty bad. But I noticed that for Festival, even though the base voices that came with it were less than 6 MB each files, other voices were available that were 70 to 80 MB files each. These larger files did offer much better sounding voices. Most of these TTS converters also ran a low sampling rate, 8 or 16 kHz typically. But the large Festival voice files typically use 32 kHz which gives much better audio results, though this is still worse than the 44.1 kHz sampling used for CDs. Festival doesn't have a graphic user's interface (GUI) that I'm aware of for Linux. Festival has to be run as text commands in an executable shell, as shown in the screenshot in Figure 1. In other words, you can't point and click your mouse to run Festival. You need to type very specific and accurate commands similar to the old DOS and Unix commands. This may intimidate most people.
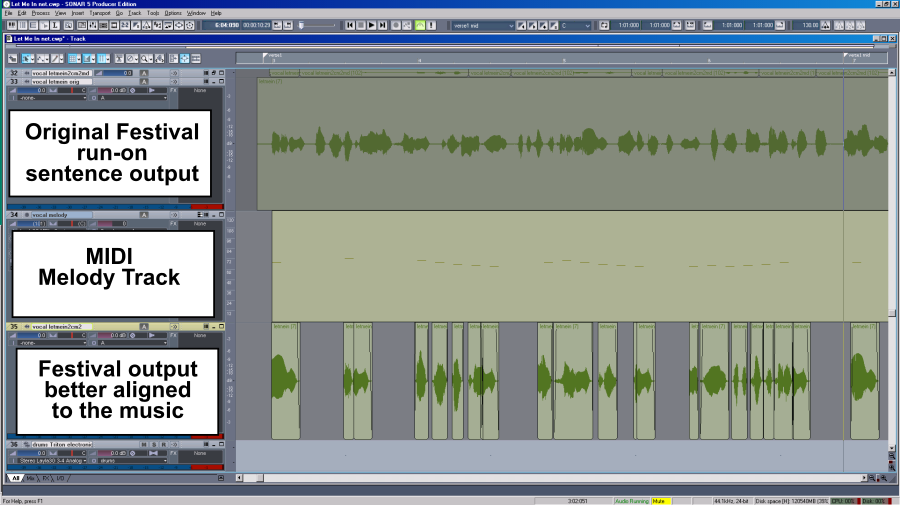
Figure 1 - Screenshot of Festival TTS software running in an executable shell. I decide to try to use one of these better sounding voices to sing one of our songs. We decided to use the song "Let Me In" as our guinea pig. This is a song we wrote originally in 1984 with some lyric changes in 2002 but never recorded. We thought the lyrics were too sappy. They also contained a bunch of what serious lyricists would consider deficiencies, such as mostly tell with little show and a lot of "Yoda-isms," where "not in a natural sequence, the words, they are." But, if a computer is to sing a "love" song, sappy, quirky lyrics are not necessarily a bad thing. Plus, a lot of teenage girls probably find these "Yoda-isms" "poetic." This is a sample of the "Let Me In" lyrics run through one of the default vocals included in the initial download package of Festival. Notice how horribly "computerized" it sounds. But this sample through one of the 70+ MB file voices sounds much more natural. But it still has some glitches and artifacts. I was able to use Sonar's audio editing capabilities to isolate and either delete or replace most all of these glitches. Sending the "Let Me In" lyrics though Festival did result in one long run-on sentence in a talking voice. I needed to change both the pitch and the timing of the words and syllables to get something sounding close to singing. I have Melodyne, which, in theory, can manipulate both the pitch and timing. But a couple trials showed that I needed to cut up this long run-on sentence and try to align the words with the music in Sonar, which has much more accurate audio waveform editing capability. Figure 2 shows a screenshot of the run-on sentence audio cut up and better aligned to the music, as heard in this audio sample. I could then use Melodyne to change the pitch and shrink or stretch the words and syllables as needed to better fit the music.
Figure 2 - Screenshot of the run-on sentence audio cut up and better aligned to the music. This is the final result. The singing does sound a bit stilted and emotionally ambiguous. The lead vocal also sounds a bit grainy and noisy compared to the rest of the music. I suspect this is due to the lower 32 kHz sampling rate and probably lower 16 resolution, compared to 44.1 kHz and 24 bit for the rest of the tracks, plus some artifacts due to the extreme pitch and syllable duration changes done in Melodyne to fit the music. But the melody and phrasing are reasonably accurate. The lyrics are also recognizable, or at least as recognizable as you can expect for pop and rock music ("Excuse me while I kiss this guy," Jimi Hendrix, maybe?). This example shows any reasonably talented singers that their jobs are still fairly secure, at least for a little while. But the singing in this song does have its own quirky sort of charm. This definitely was not plug and play. It took me about six days to generate this lead vocal track from these lyrics. A lot of that time was spent trying various TTS software, figuring out how the software worked, a lot of audio track cutting, pasting, moving, shrinking, stretching, and finding solutions to the various problems that came up. But with this experience I could probably now do a similar vocal track in a day or two. There is a "singing" option already present in the Festival program. But it requires you create a file that lists every syllable and its note and duration. The "Let Me In" lyrics contain 290 words, many multi-syllable, so over 400 lines would be needed. Few of these lyrics are repeated. Plus there is no way to handle rests, so you still have to do a lot of cutting and dragging to align the lyrics. Plus you have to take the time to figure out the note and duration of each syllable instead of just dragging it with the mouse to the right place. So this "singing" mode option was not considered practical for this song. But this mode may be a better solution for a song with a lot less lyrics and a lot of repeating lines. My next experiment may be to try to create a song with this singing mode, if I can find or write a suitable song. I did try the singing mode with some of the included examples plus some simple test lines of my own. But I couldn't get the singing mode to work, though all other modes I tried appeared to work. Another thing to play with when I get some time. [Nov. 4, 2020 update: Further investigation shows that the Festival singing option only works with the original low fidelity, low sampling rate base voices that come with Festival. The higher fidelity voices with much larger files apparently have features that can't be handled by the singing option.] © 2019, 2020 Stone Marmot Enterprises, all rights reserved. |
||